以下的内容都是 tensorflow1.x 的语法
Session 会话控制
Session 是 Tensorflow 为了控制,和输出文件的执行的语句. 运行session.run() 可以获得你要得知的运算结果, 或者是你所要运算的部分。
product 不是直接计算的步骤, 所以我们会要使用 Session 来激活 product 并得到计算结果
1 | matrix1 = tf.constant([[3,3]]) |
Variable 变量
在 TensorFlow 里,变量的定义和初始化是分开的,所有关于变量的赋值和计算都要通过tf.Session的run来进行。
将所有图变量进行集体初始化时应该使用 tf.global_variables_initializer。
1 | # 定义变量 state = tf.Variable() |
tf.get_variable(name, shape, initializer,collections):
name就是变量的名称,shape是变量的维度,initializer是变量初始化的方式,初始化的方式有以下几种:
- tf.random_normal_initializer:正态分布
- tf.constant_initializer:常量初始化函数
- …
tensorflow中,当使用tf.variable和tf.get_variable两个函数时,它们return的变量会被收集到 默认的一些 collections
constant 常量
1 | # 常量 1 |
一个TensorFlow的运算,被表示为一个数据流的图。Tensorflow中使用tf.Graph类表示可计算的图。
图是由操作Operation和张量Tensor来构成,其中Operation表示图的节点(即计算单元),而Tensor则表示图的边(即Operation之间流动的数据单元)。
1 | import tensorflow as tf |
Placeholder 传入值
placeholder 是 Tensorflow 中的占位符,暂时储存变量。
Tensorflow 如果想要从外部传入data, 那就需要用到 tf.placeholder(), 然后以这种形式传输数据 sess.run(***, feed_dict={input: **}).
当运算要用到placeholder时,就需要feed_dict这个字典来指定输入
1 | import tensorflow as tf |
tf.placeholder(dtype, shape=None, name=None)
参数:
- dtype:数据类型。常用的是tf.float32,tf.float64等数值类型
- shape:数据形状。默认是None,就是一维值,也可以是多维,比如[2,3], [None, 3]表示列是3,行不定
- name:名称。
激励函数 (Activation Function)
激励函数运行时激活神经网络中某一部分神经元,将激活信息向后传入下一层的神经系统。激励函数的实质是非线性方程。 Tensorflow 的神经网络 里面处理较为复杂的问题时都会需要运用激励函数 activation function 。
添加层 def add_layer()
在 Tensorflow 里定义一个添加层的函数可以很容易的添加神经层,为之后的添加省下不少时间。神经层里常见的参数通常有weights、biases和激励函数。
定义添加神经层的函数def add_layer(),它有四个参数:输入值、输入的大小、输出的大小和激励函数,我们设定默认的激励函数是None。
1 | def add_layer(inputs, in_size, out_size, activation_function=None): |
在机器学习中,biases的推荐值不为0.
定义Wx_plus_b, 即神经网络未激活的值.
当activation_function——激励函数为None时,输出就是当前的预测值——Wx_plus_b,不为None时,就把Wx_plus_b传到activation_function()函数中得到输出。
最后,返回输出
1 | import tensorflow as tf |
建造神经网络
建造一个完整的神经网络 , 包括添加神经层, 计算误差, 训练步骤, 判断是否在学习
导入数据 ,构建所需的数据,利用占位符定义我们所需的神经网络的输入
定义神经层 搭建网络
通常神经层都包括输入层、隐藏层和输出层。例子 :构建的是——输入层1个、隐藏层10个、输出层1个的神经网络
定义隐藏层
1 | l1 = add_layer(xs, 1, 10, activation_function=tf.nn.relu) |
定义输出层
1 | # 这里的输入10层(隐藏层) 输出一层 |
计算误差
训练
优化
优化器 optimizer 加速神经网络训练 (Speed Up Training)
加速神经网络加速过程:
- Stochastic Gradient Descent (SGD)
- Momentum
- AdaGrad
- RMSProp
- Adam
TensorBoard
TensorBoard是Tensorflow可视化工具,可以用来展现TensorFlow图像,绘制图像生成的定量指标图以及附加数据。
1 | # 在根目录下运行就好了 |
Tensorflow函数
矩阵降纬
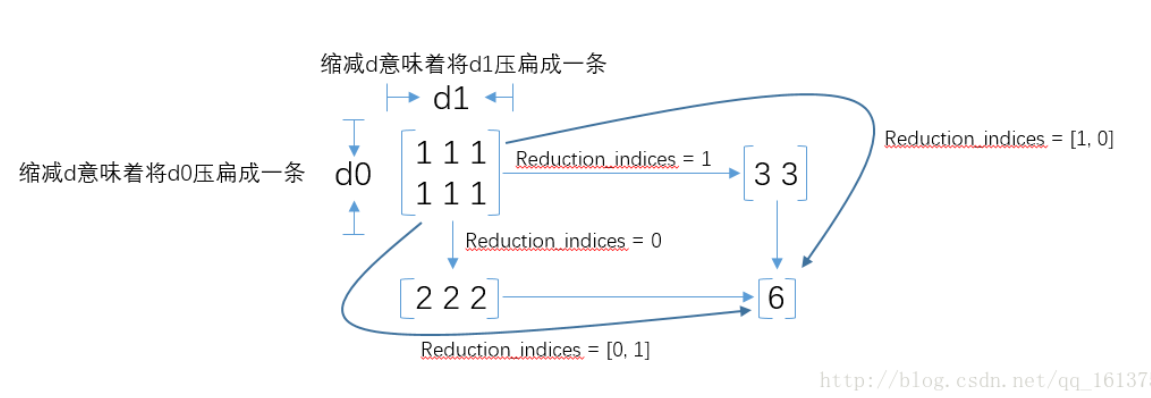
reduce_sum(arg1, arg2)
- 参数
arg1即为要求和的数据 arg2有两个取值分别为0和1,通常用reduction_indices=[0]或reduction_indices=[1]来传递参数。- 从图可以看出,当
arg2 = 0时,是纵向对矩阵求和,原来矩阵有几列就得到几个值 - 当
arg2 = 1时,是横向对矩阵求和 - 当省略
arg2参数时,默认对矩阵所有元素进行求和。
reduce_mean()
计算张量tensor沿着指定的数轴(tensor的某一维度)上的平均值
训练 (Training)
优化 (Optimizers)
tf 中各种优化类提供了为损失函数计算梯度的方法,其中包含比较经典的优化算法,比如 GradientDescent (梯度下降算法)和 Adagrad。
1 | # 实例化一个优化函数,基于learning_rate=0.1进行梯度优化训练 |
用 Session 来 run 每一次 training 的数据,逐步提升神经网络的预测准确性。
计算
tf.multiply()两个矩阵中对应元素各自相乘
tf.matmul()将矩阵a乘以矩阵b,生成a * b
我在各种网站上查了很久,发现重启一下就没有Shape [-1,1] has negative dimensions这个错,并且除了graph的其他部分也出现了
激活函数(Activation Function)
1 ) tf.nn.relu()函数
线性整流函数(Rectified Linear Unit, ReLU),又称修正线性单元。tf.nn.relu()函数的目的是,将输入小于0的值幅值为0,输入大于0的值不变。
2) tf.nn.softmax_cross_entropy_with_logits()函数
用于计算交叉熵,常用来做损失函数
3)tf.train.AdamOptimizer()函数
自适应矩估计优化算法,Adam 优化算法:是一个寻找全局最优点的优化算法,引入了二次方梯度校正