Deep Q Network 简称为 DQN,结合了Q learning 的优势 和 Neural networks 。
传统的表格形式的强化学习用表格来存储每一个状态 state, 和在这个 state 每个行为 action 所拥有的 Q 值。但是当 state 过多,存储这么多的状态数据,在这些数据中搜索并选择 action ,不仅效率低而且占内存。
神经网络可以解决这一问题。可以将状态和动作当成神经网络的输入, 然后经过神经网络分析后得到动作的 Q 值, 这样我们就没必要在表格中记录 Q 值, 而是直接使用神经网络生成 Q 值. 还有一种形式的是这样, 我们也能只输入状态值, 输出所有的动作值, 然后按照 Q learning 的原则, 直接选择拥有最大值的动作当做下一步要做的动作。
如何更新神经网络
神经网络需要被训练,才能得到准确的值,如何更新生神经网络的 NN 参数
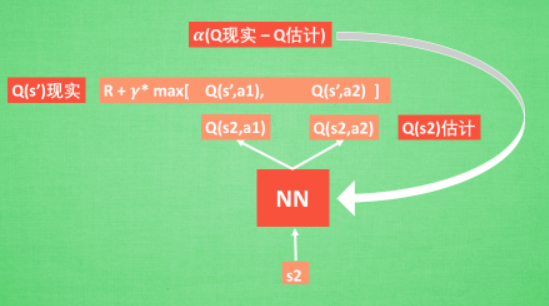
- Q 估计:输入一个状态 S2,通过 NN 预测出Q(s2, a1) 和 Q(s2,a2) 的值, 这就是 Q 估计,选取 Q 估计中最大值的动作来换取环境中的奖励 reward
- Q 现实: Q 现实中包含从神经网络分析出来的两个 Q 估计值, 不过这个 Q 估计是针对于下一步在 s’ 的估计.
- 最后再通过刚刚所说的算法更新神经网络中的参数。 新的NN = 老NN + α(Q现实 - Q估计)
DQN 两大利器
Experience replay 和 Fixed Q-targets 都是为了打经历之间的相关性,使神经网络可以更好地收敛。
Experience replay : DQN 有一个记忆库用于学习之前的经历(off-policy),所以每次 DQN 更新的时候, 我们都可以随机抽取一些之前的经历进行学习. 随机抽取这种做法打乱了经历之间的相关性, 也使得神经网络更新更有效率.
Fixed Q-targets: Fixed Q-targets 也是一种打乱相关性的机理, 如果使用 fixed Q-targets, 我们就会在 DQN 中使用到两个结构相同但参数不同的神经网络, 预测 Q 估计 的神经网络具备最新的参数, 而预测 Q 现实 的神经网络使用的参数则是很久以前的.