强化学习方法
分类一:是否理解环境:Modelfree 和 Modelbased
- Modelfree :不尝试去理解环境, 环境给了我们什么就是什么,
- Modelbased :理解了环境也就是学会了用一个模型来代表环境,会先在环境中模拟去学习
- 为真实世界建模,在虚拟环境中学习
- 通过想象来预判断接下来将要发生的所有情况. 然后选择这些想象情况中最好的那种. 并依据这种情况来采取下一步的策略
分类二:基于概率 和 基于价值
- Policy-Based RL:最直接的一种 这个概率是随机的嘛
- 通过感官分析所处的环境, 直接输出下一步要采取的各种动作的概率然后根据概率采取行动, 所以每种动作都有可能被选中, 只是可能性不同。
- Policy Gradients
- Value-Based RL
- 分析环境后,输出则是所有动作的价值, 我们会根据最高价值来选着动作。
- 基于价值的方法对于选取连续的动作是无效的。
- Q learning, Sarsa
- Actor-Critic
- actor 会基于概率做出动作, 而 critic 会对做出的动作给出动作的价值, 这样就在原有的 policy gradients 上加速了学习过程。
基于价值的决策只会选择选价值最高的,而基于概率的方法,即使某个动作的概率最高,也可能不会选择它。感觉 和 s-greedy 很相似。
分类三:回合更新和单步更新
回合更新就是,比如玩一轮游戏,从游戏开始,等到游戏结束才会总结这一回合中的转折点,然后更新行为准则。单步更新就是每走一步,就更新行为准则,单步更新效率更高。
- Monte-Carlo Update
- Monte-carlo learning 和基础版的 policy gradients
- Temporal-Difference Update
- Qlearning, Sarsa, 升级版的 policy gradients
分类四:在线学习 和 离线学习
- On-Policy(在线学习):本人在学习。
- Sarsa
- Off-Policy(离线学习) : 可以观察别人学习,学习别人的经验,也可以自己学习
- Q learning
Q Leaning
Q Leaning :基于表格的决策。Q 表,action(a)、state(s)、value(数值)

算法
整个算法就是一直不断更新 Q table 里的值, 然后再根据新的值来判断要在某个 state 采取怎样的 action。Qlearning 是一个 off-policy 的算法,
initialize Q_table (S , A, VALUE)
update environment (S)
chose an action from Q_table
tack action and get next S (S_) and R
get q_predict whose value is q_table.loc[S, A]:The value may be the maxValue or may not,for greedy-policy
get q_target
- terminal :q_target = R
- not terminal :q_target = $R + \gamma $(q_table[s_, :].max) :The value is the maxValue
update Q_table
- at begin , all value is zero,and then according to next equation to update
- 新的Q(S1,a2) = 老Q(s1,a2) + a*[q_target - q_target]
update environment again (S_)

$\epsilon$-greedy:用在决策的一种策略,比如说 3 = 0.9 的时候,90% 按照 Q 表的最优值选择行为,10% 随机选择行为。
α:是学习效率,决定这次误差有多少要被学习,< 1
r :奖励
γ : 是对未来 奖励 的衰减值
EXAMPLE
On-line 小游戏
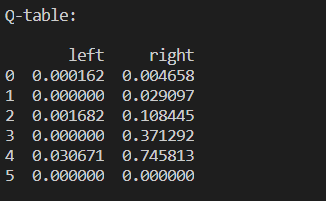
这是小游戏结束之后的 q_table,最后明显 right 的 value 大于 left。
Off-line 小游戏
这里 state 代表一个 observation,首先初始化 q_table,初始化环境获得 observation ,选择一个action,通过 observation 和 action 与环境交互,得到新的 observation_ 和 reword ,学习更新Q(observation,action)的 value,直到找到宝藏。中途如果踩到陷阱在与环境交互之后,就会结束本轮游戏,开始下一伦游戏。 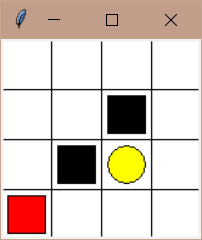
1 | def update(): |
在线学习方法
1 | #### learn 方法 |
【问题】在 choose action 时的可能,s 状态下的 action 的 value 有多个相同值,如果每次直接取最大值,那么每次就只会执行第一个最大值的 action。
【方案】打乱 state_action 的index;保留 state_action 中的最大值,利用choice() 方法随机选择。
1 | # state_action |
总结 :Q-Learning ,基于 q_table ,横轴是 state,纵轴是 action,表格的值是 q(state,action),计算 q 值的公式是
$$
Q(s,a) = Q(s,a) + {\alpha} [r + \gamma Q_{max}(s_,a_) - Q(s,a)]
$$
agent 一开始什么都不知道,目标是找到最优值 ,然后 agent 做出action (第一次是随机选择一个 action,之后就根据 q_table 选取最大值 && $\epsilon$-greedy 共同决定 action),跟环境交互之后获得新的 state_, reward, 把 state_, r 带入上面的式子,计算出新的 q值,更新q_table。不断更新q_table,多个 episode 之后,就可以熟练的找最优值