◆正则表达式概述
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
这篇文章就来介绍正则表达式的基础知识,对于正则表达式的匹配,可以用regexr这个网站进行练习和检验
1.1 正则表达式的作用
1.正则表通常被用来检索、替换那些符合某个模式(规则)的文本,例如验证表单:用户名表单只能输入英文字母、数字或者下划线,昵称输入框中可以输入中文(匹配)。
2.正则表达式还常用于过滤掉页面内容中的一些敏感词(替换)
3.从字符串中获取我们想要的特定部分的提取等。
◆正则表达式在JavaScript中的使用
在JavaScript中正则表达式也是一种对象。
2.1 创建正则表达式
在JavaScript中,可以通过两种方式创建一个正则表达式。
1.通过调用RegExp对象的构造函数创建
1 | var变量名= new RegExp (/表达式/); |
2.通过字面量创建
1 | var变量名= /表达式/ ; |
//注释中间放表达式就是正则字面量
2.2 测试正则表达式test
test() 正则对象方法 , 用于检测字符串是否符合该规则 , 该对象会返回true或false ,其参数是测试字符串。
1 | regex0bj.test (str); |
- regexObj是写的正则表达式
- str我们要测试的文本
- 就是检测str文本是否符合我们写的正则表达式规范.
◆正则表达式中的特殊字符
3.1 正则表达式的组成
一个正则表达式可以由简单的字符构成,比如/abc/,也可以是简单和特殊字符的组合,比如/ab*c/,其中特殊字符也被称为元字符,在正则表达式中是具有特殊意义的专用符号,如^、$、+等。
特殊字符非常多, 可以参考:
MDN : )https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Guide/Regular_Expressions
jQuery 手册:正则表达式部分
正则测试工 具: http://tool.oschina.net/regex
3.2 边界符
正则表达式中的边界符(位置符)用来提示字符所处的位置,主要有两个字符。
| 边界符 | 说明 |
|---|---|
| ^ | 表示匹配行首的文本(以谁开始) |
| $ | 表示匹配行尾的文本(以谁结束) |
如果 ^ 和 $ 在一起,表示必须是精确匹配。
1 | var reg = /^123$/; |
3.3 字符类
字符类表示有一系列字符可供选择 , 只要匹配其中一个就可以了。所有可供选择的字符都放在方括号内。
1.字符类: [] 表示有一系列字符可供选择,只要匹配其中一个就可以了,多选一
2.[-]方括号内部范围符-
1 | var rg = /[abc]/; // 只要包含有a 或者 包含有b 或者包含有c 都返回为true |
[^]方括号内部取反符^
1 | /^[^abc]$/ .test('a')// false |
3.4 量词符
量词符用来设定某个模式出现的次数。
[]中一次只能匹配单个字符,而使用了限定符之后,就可以指定字符重复次数。
| 形式 | 含义 | 例子 |
|---|---|---|
X? |
X,一次或一次也没有 | /y1?/g , 匹配y1和y,但不会匹配y111 |
X* |
X,零次或多次 | var reg1 = /^a*$/; |
X+ |
X,一次或多次 | /y1+/g ,匹配yoo,但不能匹配y |
X{n,m} |
X,至少 n 次,但是不超过 m 次 | /yo{2,4}/g o出现2或3或4次 , yooo |
X{n,} |
X,至少 n 次 | /yo{2,}/g o至少出现2次 , yoooo |
X{n} |
X,恰好 n 次 | /yo{2}/g o只出现两次 ,yo |
1) ? 相当于 1 || 0
1 | var reg1 = /^a?$/; |
2) * 相当于 >= 0 可以出现0次或者很多次
1 | var reg1 = /^a*$/; |
3) + 相当于 >= 1 可以出现1次或者很多次
1 | var reg1 = /^a+$/; |
4) {3 } 就是重复3次
1 | var reg = /^a{3}$/; |
5) {3, } 大于等于3
1 | var reg = /^a{3,}$/; |
6) {3,16} 大于等于3 并且 小于等于6, 量词之间不能有空格
1 | var reg = /^a{3,6}$/; |
3.5 括号总结
- 大括号 :量词符 , 里面表示重复次数
- 中括号 : 字符集合 , 匹配方括号中的任意字符.
- 小括号 : 表示优先级
1 | var reg = /^abc{3}$/; // 它只是让c重复三次 abccc |
可以在线测试:https://c.runoob.com/front-end/854
3.6 预定义类
预定义类指的是某些常见模式的简写方式。这些都是多选一。
| 字符 | 含义 |
|---|---|
| \d | 匹配数字:[0-9] |
| \D | 匹配非数字: [^0-9] |
| \s | 空白字符:[ \t \n \x0B \f \r] 空格、制表符(tab)、断行 |
| \S | 非空白字符:[^\s] |
| \w | 单词字符:[a-zA-Z0-9_] 还有下划线 |
| \W | 非单词字符:[^\w] |
| \u4e00-\u9fa5 | 使用unicode 匹配中文字符 |
案例1:用户名验证
功能需求:
如果用户名输入台法,则后面提示信息为:用户名合法,并且颜色为绿色
如果用户名输入不合法 则后面提示信息为:用户名不符合规范并且颜色为绿色
分析:
用户名只能为英文字母,数字,下划线或者短横线组成,并且用户名长度为6~16位.
首先准备好这种正则表达式模式/$[a-zA-Z0-9-_]{6,16}^/
当表单 失去焦点就开始验证.
如果符合正则规范,则让后面的span标签添加right类.
如果不符合正则规范, 则让后面的span标签添加wrong类
◆正则表达式中的替换
4.1 replace替换
replace()方法可以实现替换字符串操作,用来替换的参数可以是一个字符串或是一个正则表达式。
1 | stringObject.replace(regexp/substr,replacement) |
第一个参数:被替换的字符串或者正则表达式
第二个参数:替换为的字符串
返回值是一 个替换完毕的新字符串
首先通过一个基础例子了解正则表达式的魅力,正则表达式的 \类型\ 默认只匹配字符串的一次,如果需要全部匹配,可以通过 /g来解决。
4.2 正则表达式参数
1 | /表达式/[switch] |
switch(也称为修饰符)按照什么样的模式来匹配.有三种值:
g:全局匹配
i:忽略大小写
gi:全局匹配+忽略大小写
正则表达式中的或者符号是
|
1 | div.innerHTML = text.value.replace(/激情|gay/g, '**'); |
字符
正则的匹配
1)精准匹配字符串
/王画画/
// 内容是"王画画",则全部选中
//内容是"王画画王画画",则只匹配第一个王画画2)模糊匹配 . 点代表匹配任意字符
/王../ //只要是以‘王’开头,余下2个任意字符 组成的字符串都会被匹配通过上面的例子可以看出一个 . 代表一位任意字符。
正则表达还可以匹配各种复杂组合的字符串,接着就从正则表达式中的字符去了解它。
特殊字符
特殊字符一般含有特殊意义,而且可以组合使用。
| 特别字符 | 描述 |
|---|---|
| $ | 匹配输入字符串的结尾位置。 |
| ^ | 匹配输入字符串的开始位置,若在[]中使用,表示不接受该方括号表达式中的字符集合。 |
| \b | 匹配一个单词边界,即字与空格间的位置。也就是一个单词的第一个字符之前和最后一个字符之后的位置 |
| \B | 非单词边界匹配。 |
| . | 匹配除换行符 \n 之外的任何单字符 |
| \ | 转义字符,’n’ 匹配字符 ‘n’。’\n’ 匹配换行符。序列 ‘\‘ 匹配 “",而 ‘(‘ 则匹配 “(“。 |
| + | 匹配前面的子表达式一次或多次 |
| * | 匹配前面的子表达式零次或多次 |
| ? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。 |
| | | 指明两项之间的一个选择。 |
| ( ) | 标记一个子表达式的开始和结束位置。 |
| [ | 标记一个中括号表达式的开始 |
| { | 标记限定符表达式的开始 |
\b 和 \B的使用
通过下面的例子来认识两者的区别
当\b 出现在匹配字符串的开始

当\b 出现在匹配字符串的结尾的时候

如果我们想要匹配Google中的 oo ,就需要使用\B这个字母与字母的边界。以下两种方法都可以匹配到oo。
1 | /oo\B/ |
3 . 使用[]匹配单个字符
/[字符]/ 每次只匹配一个字符,按照前后顺序匹配。
| 形式 | 含义 |
|---|---|
| [abc] | a 或 b 或 c |
| [^abc] | 任何字符,除了 a、b 或 c(否定) |
| [a-zA-Z] | a 到 z 或 A 到 Z,两头的字母包括在内(范围) |
| [a-d[m-p]] | a 到 d 或 m 到 p:[a-dm-p](并集) |
| [a-z&&[def]] | a 到 d 或 m 到 p:[a-dm-p](并集) |
4 . 限定符
[] 中只能匹配单个字符,而使用了限定符之后,就可以指定字符重复次数。
| 形式 | 含义 | 例子 |
|---|---|---|
X? |
X,一次或一次也没有 | /y1?/g , 匹配y1和y,但不会匹配y111 |
X* |
X,零次或多次 | /y1*/g ,匹配 yoo y |
X+ |
X,一次或多次 | /y1+/g ,匹配yoo,但不能匹配y |
X{n,m} |
X,至少 n 次,但是不超过 m 次 | /yo{2,4}/g o出现2或3或4次 , yooo |
X{n,} |
X,至少 n 次 | /yo{2,}/g o至少出现2次 , yoooo |
X{n} |
X,恰好 n 次 | /yo{2}/g o只出现两次 ,yo |
贪婪
* 、 + 限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个?就可以实现非贪婪或最小匹配。
例如
1 | <h1>xxxxx11111</h1> |
当你只想选中“
”的时候,/<.*>/ 会选中上面的全部内容,这个时候可以通过非贪婪表达式去解决这一问题 。
/<.*>/ 只会匹配“
”。
通过在 ***、+** 或 ? 限定符之后放置 ?,该表达式从”贪婪”表达式转换为”非贪婪”表达式或者最小匹配。
捕获
重复单字符我们可以使用限定符,那么重复使用字符串,就需要用到分组,用小括号将字符串包裹起来,就可以限定字符串重复次数。
比如以前要匹配 lololo 是这样的
1 | /lololo/ |
有了分组之后是这样的
1 | /(lo){3}/ |
分组分为捕获分组和非捕获分组,下面就详细介绍这两种分组。
1 . 捕获分组
()表示捕获分组,()会把每个分组里的匹配的值保存起来,使用$n(n是一个数字,表示第n个捕获组的内容)。
1)候选
一个分组中可以有多个候选表达式,用|分隔,|意为“或”
1 | /(select|update|and|or)/ 匹配这些单词中的任意一个 |
2) 引用捕获
分组会被系统编号,按照 “(” 出现的顺序,从左到右,从1开始进行编号的 。
例如对 “abc”进行嵌套分组为 (a(b)) (c) ,$1就存储着第一个括号值ab,$2存储着第二个括号值b

那么如何引用被保存起来的捕获内容呢?
通过RegExp对象去引用
1 | var reg = /(\d{4})-(\d{2})-(\d{2})/ |
3)反向引用
正则表达式里可以进行反向引用。
\1引用了第一个被分组所捕获的串,本例中即(\w{3})。
1 | var reg = /(\w{3}) is \1/ |
2 . 非捕获分组
(?:)表示非捕获分组,和捕获分组唯一的区别在于,非捕获分组匹配的值不会保存起来。
通过一个例子来讲解一下捕获分组和非捕获分组的区别。
从1000¥8000$中获取出第一个金额和单位,用捕获分组直接就得到了,结果如下

如果想获得第二笔金额就要忽略掉前面的1000$,这个时候可以使用非捕获分组,结果如下

这里分享一个利用非捕获分组的例子
1 | // 数字格式化 1,123,000 |
\B是找到第一个非单词边界,即1 和 2 之间的边界
3 . 正向与反向前瞻型分组
前瞻分组会作为匹配校验,但不出现在匹配结果字符里面,而且不作为子匹配返回
1) 正向前瞻(string(?=模式)
this is a后面要跟上dog才匹配成功
1 | var reg = /this is a (?=dog)/ |
2) 反向前瞻 (string(?!模式)
this is a后面除了跟上dog,都能匹配成功
1 | var reg = /this is a (?!dog)/ |
4. 正向与反向后顾型分组
后顾型分组需要在要匹配的字符串前面使用,常结合replace使用
1)正向后顾 (?<=pattern) string
正向后顾 (?<=pattern) string表示 string 前面要有pattern
1 | /one dog/ |
上面的意思就是查找dog前面是one的,并把这个dog值替代成cat
2)负向后顾 (?<!pattern)string
反向后顾 (?<!pattern)string 表示 string 前面不能有pattern)。
1 | /two dog/ |
上面的意思就是查找dog前面不是one的,并把这个dog值替代成cat
总结
下面是一个非捕获和捕获组合使用的例子
(?:A|B) 中 A 和 B 是内部引用
/1(?:37|38)\d{4}(\d{4})/g 表示第一位是1,第二三两位是37或者38,第四-七是任意数字,后四位则是一个引用,与编号是1引用对映。
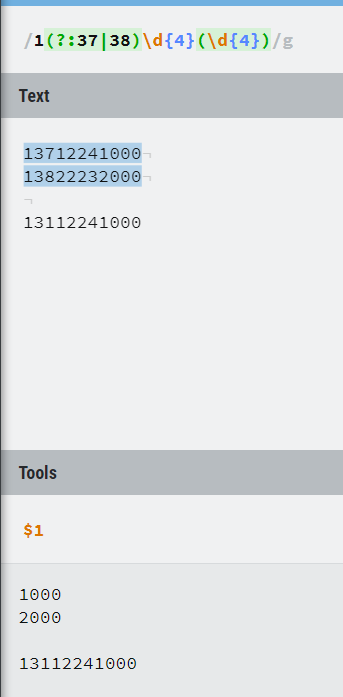
| 形式 | 含义 |
|---|---|
(?:X) |
X,作为非捕获组 ,匹配值不保存 |
string(?=X) |
正向前瞻,判断string后面是否有x |
string(?!X) |
反向后瞻,判断string后面是否没有x |
(?<=X`)string |
正向后顾, 捕获前面有x的string |
| (?<! X)string | 反向后顾, 捕获前面不是x的string |
(?>X) |
X,作为独立的非捕获组 |
| (?:A|B) | A或B,分组匹配值不保存 |
正则表达式中方法
RegExp:是正则表达式(regular expression0 )
1 . test方法
.test() 方法的返回值是布尔值,通过该值可以匹配字符串中是否存在于正则表达式相匹配的结果,如果有匹配内容,返回ture,如果没有匹配内容返回false,该方法常用于判断用户输入数据的合法性,比如检验用户名的合法性。
1 | objReg.test(objStr); |
objReg 必选项 RegExp对象名称
objStr 要进行匹配检测的字符串
2 . replace 方法
在replace方法中,可以直接获取捕获内容,例如下面把10.24/2017转化成 2017-10-24 格式。
1 | var reg = /(\d{2})\.(\d{2})\/(\d{4})/ |
replace 的迭代将违禁词转化为 *。**
比如文本是dot is a doubi,其中dot和doubi是违禁词,转换后应为*** is a *****
1 | var reg = /(dot|doubi)/g |
3. Pattern类
Pattern类用于创建一个正则表达式,也可以说创建一个匹配模式,它的构造方法是私有的,不可以直接创建,但可以通过Pattern.complie(String regex) 创建一个正则表达式。
1 | Pattern p=Pattern.compile("\\w+"); |
Pattern类只能做一些简单的匹配操作,Pattern与Matcher结合可以有更多的操作。
Matcher类只能通过Pattern.matcher(CharSequence input)方法得到该类的实例.
Matcher类提供三个匹配操作方法,三个方法均返回boolean类型,当匹配到时返回true,没匹配到则返回false
Matcher.matches()
matches()对整个字符串进行匹配,只有整个字符串都匹配了才返回true .
Matcher.lookingAt()
对前面的字符串进行匹配,只有匹配到的字符串在最前面才返回true .
Matcher.find()
对字符串进行匹配,匹配到的字符串可以在任何位置.
1 | Pattern p = Pattern.compile("\\d+");//创建一个正则表达式 |